

ČÓ─ŻæBŲź┼õ蹊┐║å╩Ę
┐ń─ŻæB蹊┐║╦ą─ųž³cį┌ė┌╚ń║╬īóČÓ─ŻæBöĄō■Ųź┼õ╔ŽŻ¼╝┤╚ń║╬īóČÓ─ŻæBą┼Žóė│╔õĄĮĮyę╗Ą─▒Ēš„┐šķgĪŻįńŲ┌蹊┐ų„ę¬Ęų│╔ā╔Ślų„ŠĆŻ║Canonical Correlation Analysis (CCA) ║═Visual Semantic Embedding (VSE)ĪŻ
CCA ŽĄ┴ąĘĮĘ©
ų„ę¬╩Ū═©▀^Ęų╬÷łDŽ±║═╬─▒ŠĄ─ correlationŻ¼╚╗║¾īółDŽ±║═╬─▒ŠĄĮ═¼ę╗┐šķgĪŻ▀@ę╗ŽĄ┴ąĄ─å¢Ņ}šō╬─═Ļ├└Ż¼Ą½╩Ūą¦╣¹ŽÓī”╔ŅČ╚īW┴ĢĘĮĘ©▀Ć╩Ūėą┤²╠ßĖ▀Ą─ĪŻļm╚╗║¾Ų┌ę▓ėą╗∙ė┌╔ŅČ╚īW┴ĢĄ─ĘĮ░Ė (DCCA)Ż¼Ą½╩Ūī”▒╚║¾├µĄ─ VSE ĘĮĘ©▀Ćėąę╗Č©▓ŅŠÓĪŻ
VSE ŽĄĮyĘĮĘ©
īółDŽ±║═╬─▒ŠĘųäe▒Ē╩Š│╔ Latent EmbeddingŻ¼╚╗║¾īóČÓ─ŻæB Latent Embedding öM║ŽĄĮ═¼ę╗┐šķgĪŻVSE ĘĮĘ©ėųčė╔ņ│÷üĒĘŪ│ŻČÓĄ─ĘĮĘ©└²╚ń SCANŻ¼PFANĪŻ▀@ą®ĘĮĘ©į┌═©ė├łD╬─Ųź┼õ╔ŽęčĮø─├ĄĮ▓╗Õeą¦╣¹ĪŻ
ļSų° pre-training ║═ self-supervised ╝╝ągį┌ CV ║═ NLP ŅIė“Ą─æ¬ė├ĪŻ2019 ─Ļķ_╩╝Ż¼ėąīWš▀ķ_╩╝ćLįć╗∙ė┌┤¾ęÄ─ŻöĄō■Ż¼╩╣ė├ŅAė¢ŠÜĄ─ BERT ─Żą═īółD╬─ą┼ŽóöM║Ž═¼ę╗┐šķgĪŻ▀@ą®ĘĮĘ©į┌═©ė├ŅIė“╚ĪĄ├║▄║├Ą─ą¦╣¹Ż¼▀@ę╗ŽĄ┴ąĄ─ĘĮĘ©┐╔ęįģó┐┤ VLBERT ▀@Ų¬ PaperĪŻ
╗∙ė┌ BERT Ą─ŅAė¢ŠÜłD╬──Żą═Ą─ų„ę¬┴„│╠Ż║
1Ż®└¹ė├łDŽ±─┐ś╦Öz£y╝╝ągŽ╚ūRäełDŽ±ųąĄ─ Region of Interests(RoIs)ĪŻ
2Ż®░č ROI «öū÷łDŽ±Ą─ tokenŻ¼║═╬─▒Š token ū÷ BERT ČÓ─ŻæB╚┌║ŽŻ¼▀@└’├µėąā╔éĆĘĮ░ĖŻ║
Single-streamŻ║ęį VLBERT ×ķ┤·▒ĒŻ¼ų▒ĮėīółDŽ± token ║═╬─▒Š token Ę┼╚ļĄĮ BERT ū÷ČÓ─ŻæB╚┌║ŽĪŻ
Cross-streamŻ║ęį ViLBERT ×ķ┤·▒ĒŻ¼īółDŽ± token ║═╬─▒Š token Ž╚ū÷│§▓ĮĄ─Į╗╗źŻ¼╚╗║¾į┌Ę┼╚ļĄĮ BERTĪŻ
╬ęéāćLįć┴╦ ViLBERT ĘĮĘ©Ż¼░l¼Fį┌═©ė├ŅIė“ą¦╣¹┤_īŹ▓╗ÕeĪŻĄ½╩Ūį┌ļŖ╔╠ŅIė“Ż¼ė╔ė┌╠ß╚ĪĄ─ ROI ▓ó▓╗└ĒŽļŻ¼ī¦ų┬ą¦╣¹Ą═ė┌ŅAŲ┌ĪŻų„ę¬įŁę“į┌ė┌Ż║
1Ż®ļŖ╔╠łDŽ± ROI ╠½╔┘
ļŖ╔╠łDŽ±«aŲĘå╬ę╗Ż¼▒│Š░║åå╬╠ß╚Ī ROI ║▄╔┘Ż¼╚ńłD 1(c)ĪŻĮyėŗüĒ┐┤Ż¼═©ė├ŅIė“ MsCoCo öĄō■Ż¼├┐ÅłłDŽ±┐╔ęį╠ß╚Ī 19.8 éĆ ROIŻ¼Ą½╩ŪļŖ╔╠ų╗─▄╠ß╚Ī 6.4 éĆ ROIĪŻ«ö╚╗╬ęéā┐╔ęįÅŖųŲ╠ß╚ĪūŅąĪĄ─ ROIŻ¼▒╚╚ń ViLBERT ę¬Ū¾į┌ 10~36 éĆŻ¼VLBERT ę¬Ū¾ 100 éĆĪŻĄ½╩Ū«öįOČ©ūŅąĪ╠ß╚ĪĄ─ ROI ║¾Ż¼ėų╠ß╚Ī┴╦╠½ČÓ┴╦ųžÅ═Ą─ ROIŻ¼┐╔ęį┐┤łD 1(e)ĪŻ
2Ż®ļŖ╔╠ ROI ▓╗ē“ fine-grained
ļŖ╔╠łDŽ±å╬ę╗Ż¼╠ß╚ĪĄ─ RoIs ų„ę¬╩Ū object-level Ą─«aŲĘ (└²╚ńŻ¼š¹¾w▀Bę┬╚╣Ż¼T-shirt Ą╚) ĪŻŽÓī”╬─▒ŠüĒšfŻ¼▓╗ē“╝Ü┴ŻČ╚ fine-grainŻ¼▒╚╚ń╬─▒Š└’├µ┐╔ęį├Ķ╩÷ų„¾wĘŪ│Ż╝Ü╣Øī┘ąį (╚ńŻ¼łAŅIŻ¼Š┼ĘųčØŻ¼Ų▀ĘųčØĄ╚Ą╚)ĪŻ▀@Š═ī¦ų┬łDŽ± ROI ▓╗ūŃęį║═╬─▒Š token Ųź┼õŻ¼┤¾╝ę┐╔ęįī”▒╚ę╗Ž┬ļŖ╔╠ŅIė“Ą─łD 1(c) ║═łD 1(d)ĪŻį┘┐┤Ž┬═©ė├ŅIė“Ą─łD 1(a) ║═łD 1(b)Ż¼─ŃĢ■░l¼F═©ė├ŅIė“║åå╬ę╗ą®Ż¼ų╗ę¬─▄īółDŽ±ųąĄ─ų„¾w║═╬─▒Š token alignment ĄĮę╗ŲŻ¼╗∙▒Š▓╗Ģ■╠½▓ŅĪŻ
3Ż®ļŖ╔╠łDŽ± ROI įļę¶╠½┤¾
╚ńłD 1(f) ųą╠ß╚ĪĄ──Ż╠žŅ^Ż¼Ņ^░lŻ¼╩ųųĖŻ¼ī”ė┌╔╠ŲĘŲź┼õüĒšfė├╠Ä▓╗┤¾ĪŻ
▀@ę▓Š═ĮŌßī┴╦Ż¼ļŖ╔╠ŅIė“ę▓▓╔ė├¼FėąĄ─ ROI ĘĮ╩ĮŻ¼▓ó▓╗─▄Ą├ĄĮĘŪ│Ż└ĒŽļĄ─ĮY╣¹ĪŻ╚ń╣¹šfŻ¼ßśī”ļŖ╔╠ŅIė“ųžą┬ė¢ŠÜę╗éĆļŖ╔╠ŅIė“Ą─ ROI ╠ß╚Ī─Żą═Ż¼ąĶę¬┤¾┴┐Ą─öĄō■ś╦ūó╣żū„ĪŻ─Ū├┤ėąø]ėą║åå╬ęūąąĄ─ĘĮĘ©ū÷łD╬─Ųź┼õöM║ŽĪŻ

FashionBERT łD╬─Ųź┼õ─Żą═
▒Š╬─╬ęéā╠ß│÷┴╦ FashionBERT łD╬─Ųź┼õ─Żą═Ż¼║╦ą─å¢Ņ}╩Ū╚ń║╬ĮŌøQļŖ╔╠ŅIė“łDŽ±╠žš„Ą─╠ß╚Ī╗“š▀▒Ē▀_ĪŻGoogle į┌ 2019 ─Ļ─Ļųą░l▒Ē┴╦ę╗Ų¬╬─š┬łDŽ±ūį▒OČĮīW┴Ģ─Żą═ selfieŻ¼ų„ę¬╦╝┬Ę╩ŪīółDŽ±ĘųĖŅ│╔ūėłDŻ¼╚╗║¾ŅA£yūėłD╬╗ų├ą┼ŽóĪŻÅ─Č°╩╣─Żą═▀_ĄĮ└ĒĮŌłDŽ±╠žš„Ą──┐Ą─Ż¼▀@éĆ╣żū„ī”╬ęéāåó░l║▄┤¾ĪŻ╬ęéāų▒ĮėīółDŽ± split ŽÓ═¼┤¾ąĪĄ─ PatchŻ¼╚╗║¾īó Patch ū„×ķłDŽ±Ą─ tokenŻ¼║═╬─▒Š▀MąąöM║ŽŻ¼╚ńłDČ■╦∙╩ŠĪŻ╩╣ė├ Patch Ą─║├╠ÄŻ║
łDŽ± Patch ░³║¼┴╦╦∙ėąłDŽ±Ą─╝Ü╣Øą┼ŽóĪŻ
łDŽ± Patch ▓╗Ģ■│÷¼FųžÅ═Ą─ ROI ╗“š▀╠½ČÓ¤oė├Ą─ ROIĪŻ
łDŽ± Patch ╩Ū╠ņ╚╗░³║¼Ēśą“Ą─Ż¼╦∙ęįĮŌøQ BERT Ą─ sequence å¢Ņ}ĪŻ
FashionBERT š¹¾wĮYśŗ╚ńłD 2Ż¼ų„ę¬░³└© Text Embedding, Patch Embedding, Cross-modality FashionBERTŻ¼ęį╝░ Pretrain TasksĪŻ
Text Embedding
║═įŁ╩╝ BERT ę╗śėŻ¼Ž╚īóŠõūėĘų│╔ TokenŻ¼╚╗║¾╬ęéā▓╔ė├ Whole Word Masking ╝╝ągīóš¹éĆ Token ▀Mąą maskingĪŻMasking Ą─▓▀┬į║═įŁ╩╝Ą─ BERT ▒Ż│ųę╗ų┬ĪŻ
Patch Embedding
║═ Text Embedding ŅÉ╦ŲŻ¼▀@└’╬ęéāīółDŲ¼ŲĮŠ∙Ęų│╔ 8*8 éĆ patchĪŻ├┐éĆ Patch Įø▀^ ResNet ╠ß╚Ī patch Ą─łDŽ±╠žš„Ż¼╬ęéā╠ß╚Ī 2048 ŠSłDŽ±╠žš„ĪŻPatch mask ▓▀┬įŻ¼╬ęéāļSÖC masked 10% Ą─ patchŻ¼masked Ą─ patch ė├ 0 ┤·╠µĪŻ═¼Ģrį┌ Segment ūųČ╬╬ęéāĘųäeė├ "T" ║═ "I" ģ^Ęų╬─ ▒Štoken ▌ö╚ļ║═łDŽ± patch ▌ö╚ļĪŻ
Cross-modality FashionBERT
▓╔ė├ŅAė¢ŠÜĄ─ BERT ×ķŠWĮjŻ¼▀@śėšZčį─Żą═╠ņ╚╗░³║¼į┌ FashionBERT ųąĪŻ─Żą═┐╔ęįĖ³╝ėĻPūółD╬─Ųź┼õ╚┌║ŽĪŻ
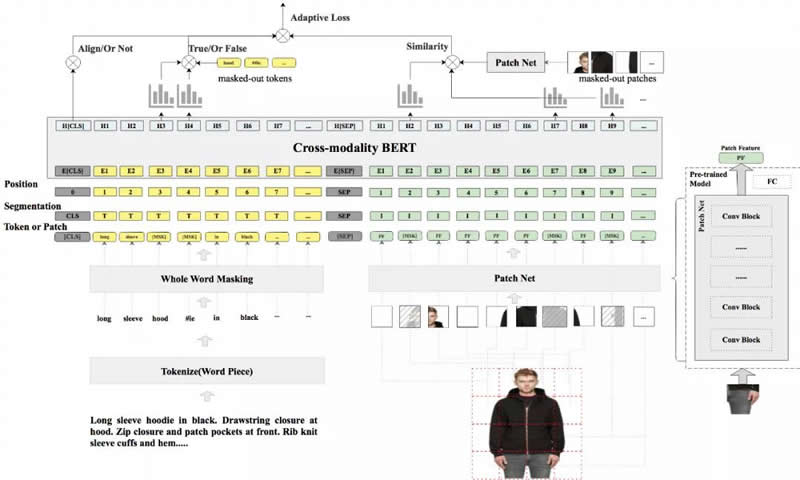
FashionBERT ─Żą═į┌ pretrain ļAČ╬Ż¼┐é╣▓░³║¼┴╦╚²éĆ╚╬䚯║
1 Masked Language Modeling (MLM)
ŅA£y Masked Text TokenŻ¼▀@éĆ╚╬äšė¢ŠÜ║═ģóöĄ╬ęéā▒Ż│ų║═įŁ╩╝Ą─ BERT ę╗ų┬ĪŻ
2 Masked Patch Modeling (MPM)
ŅA£y Masked PatchŻ¼▀@éĆ╚╬äš║═ MLM ŅÉ╦ŲĪŻĄ½╩Ūė╔ė┌łDŽ±ųąø]ėą id ╗»Ą─ tokenĪŻ▀@└’╬ęéāė├ patch ū„×ķ─┐ś╦Ż¼ŽŻ═¹ BERT ┐╔ęįųžśŗ patch ą┼ŽóŻ¼▀@└’╬ęéā▀xė├┴╦ KLD ū„×ķ loss ║»öĄĪŻ
3 Text and Image Alignment
║═ Next Sentence Prediction ╚╬äšŅÉ╦ŲŻ¼ŅA£yłD╬─╩ŪʱŲź┼õĪŻš²śė▒Š╩Ū«aŲĘś╦Ņ}║═łDŲ¼Ż¼žōśė▒Š╬ęéāļSÖC▓╔śė═¼ŅÉ─┐Ž┬Ųõ╦¹«aŲĘĄ─łDŲ¼ū„×ķžōśė▒ŠĪŻ
▀@╩Ūę╗éĆČÓ╚╬äšīW┴Ģå¢Ņ}Ż¼╚ń║╬ŲĮ║Ō▀@ą®╚╬䚥─īW┴ĢÖÓųž─žŻ┐┴Ē═ŌŻ¼▀Ćėąę╗éĆå¢Ņ}Ż¼─┐Ū░║▄ČÓīŹ“×ųĖ│÷ BERT ųą NSP Ą─ą¦╣¹▓ó▓╗ę╗Č©ĘŪ│Żėąą¦Ż¼ī”ūŅĮKĄ─ĮY╣¹Ą─ė░Ēæ▓╗╩Ū╠žäe├„└╩ĪŻĄ½╩Ūī”ė┌łD╬─Ųź┼õüĒšfŻ¼Text and Image Alignment ▀@éĆ loss ╩Ūų┴ĻPųžę¬Ą─ĪŻ─Ū├┤╚ń║╬ŲĮ║Ō▀@ÄūéĆ╚╬䚥─īW┴Ģ─žŻ┐▀@└’╬ęéā╠ß│÷ adaptive loss ╦ŃĘ©Ż¼╬ęéāīóīW┴Ģ╚╬䚥─ÖÓųž┐┤ū÷╩Ūę╗éĆą┬Ą─ā×╗»å¢Ņ}Ż¼╚ńłD 3 ╦∙╩ŠĪŻFashionBERT Ą─ loss ╩Ūš¹¾w loss Ą─╝ė║═Ż¼ė╔ė┌ų╗ėą╚²éĆ╚╬䚯¼ŲõīŹ╬ęéā┐╔ęįų▒ĮėĄ├ĄĮ╚╬äšÖÓųž W Ą─ĮŌ╬÷ĮŌ(Š▀¾wĄ─Ū¾ĮŌ▀^│╠┐╔ęįģó┐╝╬ęéāšō╬─Ż¼▀@└’▓╗į┘┘ś╩÷)ĪŻ
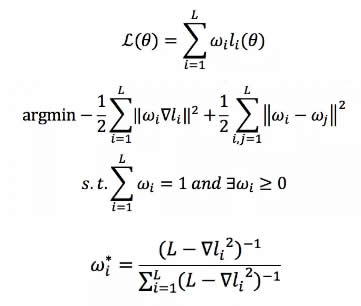
š¹éĆ w Ą─īW┴Ģ▀^│╠┐╔ęį┐┤ū÷╩Ūę╗éĆīW╔·ŽļīW┴Ģ╚²ķT╣”šnŻ¼w Ą─ū„ė├╩Ū┐žųŲīW┴ĢĄ─ĻPūóČ╚Ż¼ę╗ĘĮ├µ┐žųŲäeŲ½┐ŲŻ¼ę╗ĘĮ├µ┐é│╔┐āę¬▀_ĄĮūŅĖ▀ĪŻŠ▀¾w adaptive loss ╦ŃĘ©Ż¼┐╔ęįģó┐┤šō╬─ĪŻÅ─īŹļHĄ─ą¦╣¹üĒ┐┤ wŻ¼ļSų°ė¢ŠÜĄ─Ą³┤·ĻPūó▓╗═¼Ą─╚╬䚯¼▀_ĄĮī”╚╬äšū÷ŲĮ║ŌĄ──┐Ą─ĪŻ
śIäšæ¬ė├
─┐Ū░ FashionBERT ęčĮøķ_╩╝į┌ Alibaba ╦č╦„ČÓ─ŻæBŽ“┴┐Öz╦„╔Žæ¬ė├Ż¼ī”ė┌╦č╦„ČÓ─ŻæBŽ“┴┐Öz╦„üĒšfŻ¼Ųź┼õ╚╬äš┐╔ęį┐┤│╔╩Ūę╗éĆ╬─╬─łDŲź┼õ╚╬䚯¼╝┤ User Query (Text)-Product Title (Text) - Product Image (Image) ╚²į¬Ųź┼õĻPŽĄĪŻFashionBERT Å─╔Ž├µĄ──Żą═┐╔ęį┐┤ĄĮ╩Ūę╗éĆ╗∙ĄAĄ─łD╬─Ųź┼õ─Żą═Ż¼ę“┤╦╬ęéāū÷┴╦ Continue Pretrain ╣żū„Ż¼═¼Ģr╝ė╚ļ QueryŻ¼TitleŻ¼Image Segment ģ^ĘųŻ¼╚ńłD╦─╦∙╩ŠĪŻ║═ FashionBERT ūŅ┤¾Ą─ģ^äeį┌ė┌╬ęéāę²╚ļ╚²éĆ segment ŅÉą═Ż¼Ī░QĪ▒Ż¼Ī░TĪ▒Ż¼Ī░IĪ▒ Ęųäe┤·▒Ē QueryŻ¼TitleŻ¼ImageĪŻ
 |
| ╔╠ė├ÖCŲ„╚╦ Disinfection Robot š╣ÅdÖCŲ„╚╦ ųŪ─▄└¼╗°šŠ ▌å╩ĮÖCŲ„╚╦Ąū▒P ėŁ┘eÖCŲ„╚╦ ęŲäėÖCŲ„╚╦Ąū▒P ųvĮŌÖCŲ„╚╦ ūŽ═ŌŠĆŽ¹ČŠÖCŲ„╚╦ ┤¾Ų┴ÖCŲ„╚╦ ņF╗»Ž¹ČŠÖCŲ„╚╦ Ę■äšÖCŲ„╚╦Ąū▒P ųŪ─▄╦═▓═ÖCŲ„╚╦ ņF╗»Ž¹ČŠÖC ÖCŲ„╚╦OEM┤·╣żÅS Ž¹ČŠÖCŲ„╚╦┼┼├¹ ųŪ─▄┼õ╦═ÖCŲ„╚╦ łDĢ°^ÖCŲ„╚╦ ī¦ę²ÖCŲ„╚╦ ęŲäėŽ¹ČŠÖCŲ„╚╦ ī¦į\ÖCŲ„╚╦ ėŁ┘eĮė┤²ÖCŲ„╚╦ Ū░┼_ÖCŲ„╚╦ ī¦ė[ÖCŲ„╚╦ ŠŲĄĻ╦═╬’ÖCŲ„╚╦ įŲ█E┐Ų╝╝ØÖÖCŲ„╚╦ įŲ█EŠŲĄĻÖCŲ„╚╦ ųŪ─▄ī¦į\ÖCŲ„╚╦ |



